卢亮最近忙什么呢?BLOG也很久没更新了。上周的一次小聚才了解到:原来他一直在准备自动类聚技术,利用自动类聚技术改进一些现有BLOG发布系统的关联机制:
1 文章的自动分类:
实现类似于目前news.google.com首页那样的自动主题分类,目前初步规划是将内容分成10个大类,据说目前的精确度已经在95%以上;
2 相关文章功能:
类似于很多门户网站新闻那样的相关新闻,不要小看每篇新闻中那后面几篇相关新闻:在没有全文索引机制之前,像新闻这样的发布系统管理的文章之间的关联是很少的(孤岛),所以每篇新闻的生命周期只有短短的2天(从首页上下去以后,除了用户主动搜索就很少有被再次访问到的机会了)。BLOG也是类似的问题,要知道:用户的注意力是稀缺资源,只有少数的BLOGGER的内容能得到足够的注意力/反馈,很多人开始BLOG后,都是由于无法得到足够的反馈而放弃了。BlogChina上每天上万的发布量,但是真正能被其他人看到的却是非常少的。而相关文章:无疑是一种增加内容之间相互联系/反馈很有效的机制。
更让我佩服的是卢亮的太太:明珠,她是目前这些应用的主要实现者。
tag.bokee.com是第一步,让用户自己定义TAG作为关键词,如果用户没有输入TAG,则利用自动主题提取机制将内容类聚在一起。这部分的应用在BlogChina每篇文章后面的“手拉手”模块中。而再下一步:可能就是类似于AdSense那样的上下文广告关联了吧,将所有的浏览行为都变成了一次隐含的搜索。
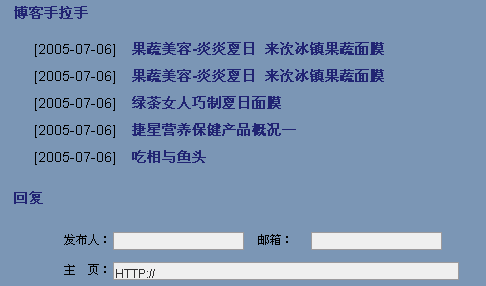
根据我目前观察:TAG仍然是质量非常高的主题提取机制,毕竟经过人工编辑的文章主题还是非常明确的。
渴望“寻找到同类”是人的一种基本需求,如何在这个充满了“噪音”的世界中将内容相互之间更好地相互组织/引用起来的确是一件比较复杂的事情:不只是新闻网站的内部在想办法实现文章之间的相互引用/关联,只要稍微观察一下,你就可以发现其实更多实现“相关文章”引用机制的努力:
BLOG的内部引用聚合
我使用的是MT的related entry plugin
安装方法查找一下MTRelatedEntriesByKeyword
需要在模板中加入:
<MTRelatedEntriesByKeyword>
<ul>
相关文章:
<MTEntries lastn="5">
<li><a href="<MTEntryLink>"><$MTEntryTitle$></a>
<$MTEntryDate format="%Y/%m/%d"$></li>
</MTEntries>
</ul>
</MTRelatedEntriesByKeyword>
这个和很多新闻网站的发布机制类似:这个方式需要作者主动给每篇文章加入多个关键词实现文章和文章之间的多对多分类。
BLOG的外部引用聚合: TrackBack
很多BLOG都允许外部引用者向自身发送引用通知(TrackBack ping),从而将“未知”引用者的能动态的聚合到自己的文章下面。
此外:基于第三方的“相关文章”实现:
通过TechnoRati的相关文章
很多blog之间通过TechnoRati的TAG登记进行主动聚合:
Blogger之间通过一些特定关键词标记:
<a href="http://apple.com/ipod" rel="tag">iPod</a>
<a href="http://en.wikipedia.org/wiki/Gravity" rel="tag">Gravity</a>
<a href="http://flickr.com/photos/tags/chihuahua" rel="tag">Chihuahua</a>
将文章“登记”在TechnoRati服务器上,然后通过这些特定关键词的搜索:就能将各种特定的主题汇聚起来,
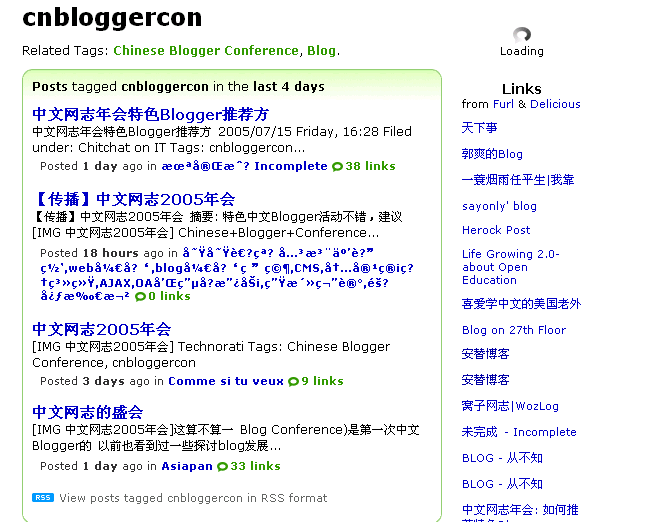
为了搜索/聚合方便,Blogger之间还充分利用了:CamelWord造词机制,比较有名的:吾城十处 通过这样的造词,对10placesofmycity相当于一次"10 places of my city"这样的短语检索,会比10 places of my city这样的全文检索更精确和方便实现:TAG检索其实是可以非常方便的通过传统数据库引擎实现的。
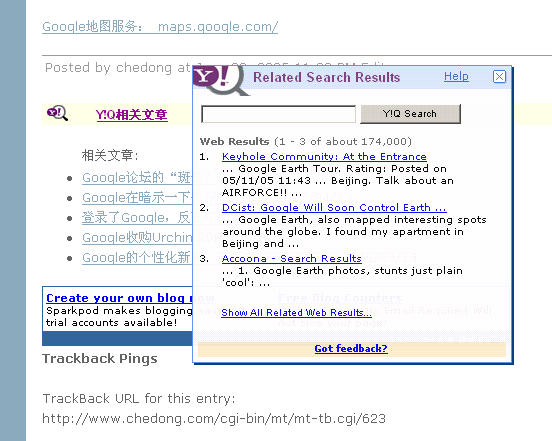
但是互联网大部分内容还是缺乏用户主动主题提取的,这时候Y!Q就是一个很方便的主题搜索工具(修正javascript escape()函数错误的版本很快就会发布了)。
基于Y!Q的主题搜索
Y!Q的原理是这样:网站自己不用自己提取每篇文章的主题关键词/TAG,只需将当前文章的部分段落文字,或者简单的将文章标题发送给Y!Q服务器,服务器从这些文字中自动提取主题,然后在全网中进行主题搜索。
相关文章引用机制的最重要的还是主题词的提取,我了解到的提取主题词主要有以下一些途径:
1 内容作者的编辑主动输入:这是缺点是不一定所有的人都有耐心提取主题/tag 我在MT中设置了自己输入关键词还是改了MT的缺省编辑模板才实现的
2 利用REFERER中的搜索引擎来源关键词统计:
缺点,不一定所有的内容都能得到搜索来源,而且文章发表的时候无法得到关键词;
3 简单算法提取:从订阅的WSJ看:感觉就是提取标题中的头2,3个名词,看来标题还是非常重要的特征来源;
4 自动主题提取:
4.1 中文分词:分词是的基础,引申的人名/地名的识别也是需要加入一些特别的权重;
4.2 词频统计:排除噪音词,就是大部分文章中都会出现的高频词;
4.3 相似度分析(Likelihood):相关文章机制的实现不仅要将相近主题的内容类聚起来,还要将几乎完全一样的内容排重。
5 结果分类:和分光棱镜一样的效果。

小结:
基于自动摘要/分类的相关引用为CMS内部和CMS之间提供了一种内容自动发现机制,通过当前文章可以动态的发现更多其他的参考。从而实现:
良好引用,良好结构,良好导航 Well organized, Well referenced, with easy navigation!。
版权声明:可以转载,转载时请务必以超链接形式标明文章 自动摘要/分类技术在CMS中的应用 的原始出处和作者信息及本版权声明。
http://www.chedong.com/blog/archives/000900.html

Comments
TRS就是做这方面东西的,以前用过他们的产品,但没有深入研究。
由: Andy 发表于 2005年07月18日 下午02时30分
自动聚类或手工聚类各有优缺点,Wiki就是一个手工聚类的好例子。世界上有价值的东西并不多,手工整理一下往往更有效。
由: Hh 发表于 2005年07月18日 下午03时51分
我觉得现在分类技术最实用的是在音乐播放器里面的歌曲分类。
由: Hyuhui 发表于 2005年07月18日 晚上10时03分
为什么我设置好后,出现的链接并不是我设的TAG类别,而都是此篇文章前面所有的文章链接。
由: Danny 发表于 2005年07月24日 夜间01时35分
每次看你的文章总是很有收获,呵呵。
由: 汤汤 发表于 2006年11月08日 下午04时18分