昨天Google发布了BlogSearch
正确的提交自己的RSS还是要通过SiteMaps:
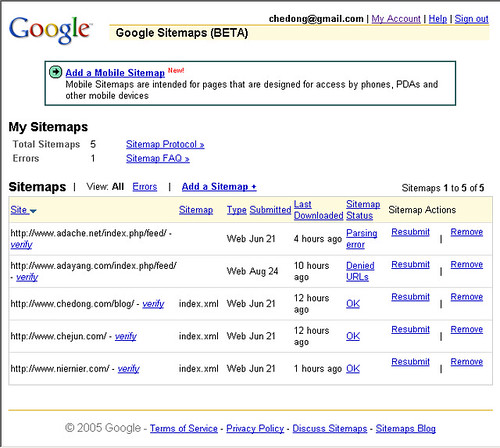
今天重新用了一下Google的SiteMaps网站:使用了一下提交网站认领(确认)功能。通过SiteMaps服务,网站管理员可以看到自己网站被Google抓取的情况。
具体的方法如下:Googlebot要求你在网站的FEED目录下创建一个空文件名,比如:
确认网站: http://www.niernier.com/
Google 已经抓取了您的网站 http://www.niernier.com/ ,并将向您展示某些结果。然而,为确保我们不会将您网站的隐私信息透露给他人,我们需要确认您的所有权。
1. 创建一个确认文件
创建名为 GOOGLE1cd1cd73cbe423a2.html 的空文件。该文件使 Google 可以对您进行唯一确认。您可以在任何文本编辑器中创建该文件。该文件应为空,因为我们只是检查其是否与您的 Sitemaps 位于同一位置,而不会阅读其内容。 您可以在 此处阅读有关此文件的详细信息。
2. 上传确认文件
您创建确认文件后,放置在您服务器上的 http://www.niernier.com/。
确认状态: http://www.niernier.com/GOOGLE1cd1cd73cbe423a2.html 已确认 查看网站状态 »
« 返回我的 Sitemaps
在网站上创建这个文件(比如用touch)后:GOOGLE1cd1cd73cbe423a2.html
点击“检查”Googlebot会立刻访问这个文件:记录到的日志如下
66.249.65.141 - - [15/Sep/2005:16:13:27 +0800] "HEAD /GOOGLE1cd1cd73cbe423a2.html HTTP/1.1" 200 0 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
Googlebot真是够省的,连内容都不要,只要HTTP HEAD中发现这个文件存在即可。
如果成功:这个网站是你的了!网站被认领的好处在于你可以看到Googlebot的访问日志:从而帮助你的网站进行死链检查。
比如我的网站的“ 统计信息”如下:
网站: http://www.chedong.com/blog/
在我们的常规抓取过程中发现的网址
作为我们常规抓取过程的一部分,我们一直在抓取您的网站。这包括来自您的网页以及其他网站网页的以下链接。 以下我们列出了在此抓取过程中无法访问的网址,以及解释我们为什么无法访问的链接。
网址 错误
http://www.chedong.com/blog/archives/000019.html HTTP 错误
http://www.chedong.com/blog/archives/000020.html HTTP 错误
http://www.chedong.com/blog/archives/000027.html HTTP 错误
今天回头再看: SiteMaps的意义感觉卢亮说的还挺对的,这种和SPIDER的即时交互是以前没有过的体验。
作者:车东 发表于:2005-09-15 16:09 最后更新于:2007-12-19 23:12版权声明:可以转载,转载时请务必以超链接形式标明文章 通过Google webmasters tools提交SiteMaps:和Googlebot直接对话 的原始出处和作者信息及本版权声明。
http://www.chedong.com/blog/archives/000993.html

Comments
这么说,我申请的Y!360就不能在sitemaps上提交了?因为我无法在360的服务器上创建一个确认文件啊。
回复:
是的,MSN Spaces也不行。
由: BITttGG 发表于 2005年09月16日 下午04时00分
请你告诉我怎么建立SITEMAPS文件呢?
我想建立一个文件
回复: Tian
提交自己的RSS到
http://www.google.com/webmasters/sitemaps/
由: Tian 发表于 2005年10月26日 下午03时54分
Hello. 推荐sitebases协议,可以更加节约带宽。
http://www.sitebases.org
谢谢。
由: Hong Xiaowan 发表于 2006年12月04日 晚上10时34分