2 Geek's blog slogan
今天查MagpieRSS的资料的时候看到了这个BLOGThe Fishbowl: 他的座右铭: tail -f /dev/mind > blog 让我一下子想起了Jeremy Zawodny's blog
SELECT * FROM random_thoughts ORDER BY date DESC
« 2005年10月 | (回到Blog入口) | 2005年12月 »
今天查MagpieRSS的资料的时候看到了这个BLOGThe Fishbowl: 他的座右铭: tail -f /dev/mind > blog 让我一下子想起了Jeremy Zawodny's blog
SELECT * FROM random_thoughts ORDER BY date DESC
谢谢HeRock的帮助,重要等到了Zoundry的邀请。
以下是工作界面截图:
这个工具对于Web开发者来说真是太方便了:LinkChecker - Firefox link validator extension for web developers
安装上插件后,右键一点就开始对当前页进行检查了:在自己的首页上试了一下
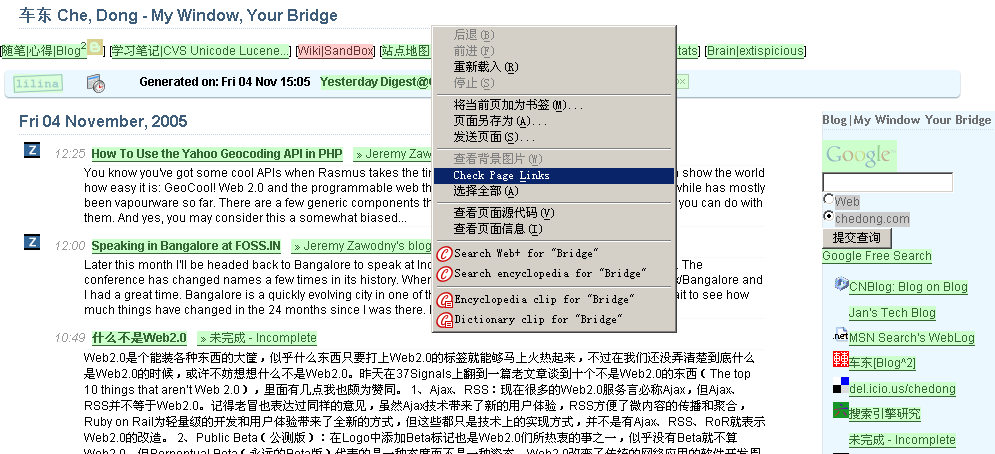
绿色:Good
红色:死链
黄色:转向/禁止访问
灰色:忽略链接,锚链或者邮件地址等
感谢RainX的推荐。
按此阅读全文 "FireFox死链检查插件:LinkChecker - Firefox link validator extension for web developers" »
今天在中文网志大会上遇到了很多朋友,其中有来自台湾Yam的Vista。 介绍了目前在台湾出现的一种公益事业捐助方式:顺手捐发票。 台湾的发票也是抽奖的,不过不是刮刮卡,而是月底对发票号。这样很多人月底的时候往往积累的很多发票。 人们可以将发票捐助给公益事业机构,由公益事业机构享受这些发票的兑奖,叫做顺手捐发票。
在国内很多地区的发票也已经是抽奖方式发布了,但的确有时候也有为兑出来的奖10元要花上半天时间领取的“鸡肋”问题。如果能将平时的发票汇总起来也省去不少浪费在兑奖方面的麻烦。比如:在一些大厦里做一些发票回收箱,汇集大家午餐开出的中奖发票,捐助慈善事业。也能促进大家开发票的积极性。
和Vista聊天的时候知道最近台湾很火的一本书《蓝海策略》

想法是这样的:
提倡競爭力以來,企業激烈競爭但結果卻是全輸,本書作者金偉燦提出新的觀點-無人競爭。尋求不同的利基,避免血流成河的紅海策略,而開創無人競爭的全新市場。本書提出的是「不靠競爭而取勝」(Winning by Not Competing)的全新策略思維。
摘自:藍海策略
本書兩位作者都任教於法國最負盛名的INSEAD 商學院,他們研究百年來三十家企業體的一百五十個策略個案,發現割喉式的競爭只會造成一片血海;真正獲利的企業徹底甩開對手自闢沒有競爭的新市場。藍海策略強調價值的重塑和創新,而不偏執於技術創新或是突破性科技發展。作者指出,能夠超越競爭的成功的企業,不是去挖掘自己的顧客需要什麼;而是研究非顧客的需求。過去企業在紅海中廝殺,彼此競爭的是價格,只能靠大量生產、降低售價來獲取利潤。本書提出,成功的企業應同時追求差異化和低成本,創造出屬於自己的市場。
更新:
2005-11-07
谢谢吕欣欣: 书收到了,简体中文版译名《蓝海战略》
2005-11-08
感谢Vista: 谢谢书摘和PPT
这里有一个图标和链接的生成器:
http://my.yahoo.com/s/button.html
选择图标,输入自己Blog的地址,代码就生成了。
Blog发布工具/系统一直是让blogger相互联系起来很重要的一个方面,因为写网志首先要解决的就是要有写作的平台。在中文网志年会上:我见到了很多人,其中很多人的网志都是我以前在使用BLOG/开发CMS过程中学习参考过的。不是blog的发展历史,只是简单回顾一下我这几年来观察到的伴随blogger们一起成长的CMS工具的演变。
自助工具篇
最早写blog的朋友很多都是自己架设CMS(内容管理系统的)的。想想2年前(大约2003年的时候)吧:各种blog的发布系统还远远不如今天这么成熟,当时Blogger之间讨论很多都是关于各种后台系统的技术问题,回顾一下当时流行的blog的发布系统:年会上见到峨桥本人让我真有一种百感交集的感觉:因为第一次使用b2就是“峨桥,不是一座桥”上看到的,网上关于phpNuke和其他几种基于PHP的发布系统他都有非常深入的实践和研究。由于B2本身架构设计的限制后来一直没有太多的发展,看到峨桥最后也转向了使用WordPress。另外我也很佩服毛向辉:自己用ASP.NET写了一套非常灵活的发布系统,不知道目前是否仍在使用,反正很多机制,如:RSS trackback都是有的,评论用了第三方的服务,当时甚至使用access数据库完成了gRaSSland搜索引擎的第一版。由于方兴东对alwayson创始人的推崇,我也了解了一下pMachine;此外:高春晖选择了:Nucleus ,至今还在用。而CSDN和Donews应该是.TEXT这套基于.NET的在中国最成功的实例;
最后我和大部分人一样:选择了搜索引擎上最流行的blog发布系统:MovableType,这里要感谢Udoo将自己架设blog的过程发布共享出来,我第一次使用MT也是参考了他的帮助,下了很大决心才完成的。而四年的成就:SixApart公司的MovableType有目共睹。目前这个是2003年底开始使用,最早为2.x系列做界面翻译的是台湾的Jedi(最近刚退役回来),而目前3.x系列的中文版本则是平生一笑提供的。中间我曾经尝试了无数的插件和方法来解决comments spam问题,在最新的3.2版本中,这个问题似乎得到了一点控制。未来的赢家看上去更像是WordPress,今年年中的时候尝试了一下WordPress,感觉的确安装非常方便,由于PHP本身比Perl的学习成本低很多,用户也更广范一些。相信WP一定有更美好的未来。
更多内容还在后面....
感觉Google Groups一直是上下文匹配技术的试验田:除了文章列表右侧有动态的AdSense广告和相关网页内容提示外,我今天在论坛的后台管理界面中也看到了相关论坛。(不知道这2天后台管理一直不能用是不是这个原因。)
在没有相关论坛功能之前:大部分论坛全部都是“孤岛”,而基于主题自动提取的分类/类聚机制无疑会加大论坛之间的交互,
1. 不说“不可能”三个字。
2. 凡事第一反应:找方法,而不是找借口。
3. 遇到挫折对自己大声说:太棒了!
4. 不说消极的话,不落入消极情绪,一旦出现立即正面处理。
5. 凡事先订立目标,并且尽量制作“梦想版”。
6. 凡事预先作计划,尽量将目标视觉化。
7. 工作时间。每一分,每一秒都做有利于生产的事情。
8. 随时用零碎的时间(如等人、排队等)做零碎的事情。
9. 守时。
10. 写下来,不要太依靠脑袋记忆。
11. 随时记录灵感。
12. 把重要的观念,方法写下来,并贴起来,以随时提示自己。
13. 走路比平时快30%,走路时脚尖稍用力推进,肢体语言健康有力,不懒散,萎靡。
14. 每天出门照镜子,给自己一个自信的微笑。
15. 每天自我反省一次。
16. 每天坚持一次运动。
17. 听心跳一分钟,指在做重要事情前,疲劳时,心情烦躁时,紧张时。
18. 开会坐在前排。
19. 微笑。
20. 用心倾听,不打断对方说话。
21. 说话时声音有力。感觉自己声音似乎能产生有感染力的磁场。
22. 说话之前,先考虑一下对方的感受。
23. 每天有意识,真诚地赞美别人三次以上。
24. 及时写感谢卡,哪怕是用便笺写。
25. 不用训斥,指责的口吻跟别人说话。
26. 控制住不要让自己做出为自己辩护的第一反应。
27. 每天做一件“分外事”。
28. 不管任何方面,每天必须至少做一次“进步一点点”。
29. 每天提前15分钟上班,推迟30分钟下班。
30. 每天在下班前用5分钟的时间做一天的整理工作。
31. 定期存钱。
32. 节俭。
33. 时常运用“头脑风暴”。
34. 恪守诚信,说到做到。
cnblog的非功利性一直是吸引很多人参与的原因,在这次网志年会上:也给另外一些很有创意的公益组织一个展示的机会。比如:
多背一公斤(1kg.cn)

有一个很好的办法宣传多背一公斤项目:就是利用你的MSN头像
http://msn.1kg.cn
另外一个是微笑图书室:让没书的孩子有书看,让你的书找到看书的孩子。
以上2个网站的赞助商里我都看到了BlogBus
年会上Sabrina拿了一件Tshirt后找了许多blogger签名,然后委托我们竞拍,并将拍卖获得的款项捐给微笑图书室和多背一公斤两个公益项目。
中文网志年会签名T恤拍卖中,我和Ada出价 360¥。
曾经介绍过给自己的Blog加上Y!Q用于在互联网上搜索搜索相关文章http://www.chedong.com/blog/archives/000910.html,但目前Y!Q对于中文的支持有限,而且实时性很差。我暂时从模板中去掉了。其实猫叔介绍过另外一个将MT内部文章通过关键词(Tagging)相互串连起来的机制。那个插件叫做MTRelatedEntries ByKeyword。原理就是利用MT的关键词字段,设置多个tagging,从而达到文章之间多对多的分类组合。
1 打开关键词编辑,MT的文章编辑界面中,缺省是不包括关键词字段显示的:需要自己“定制此窗口的显示方式”
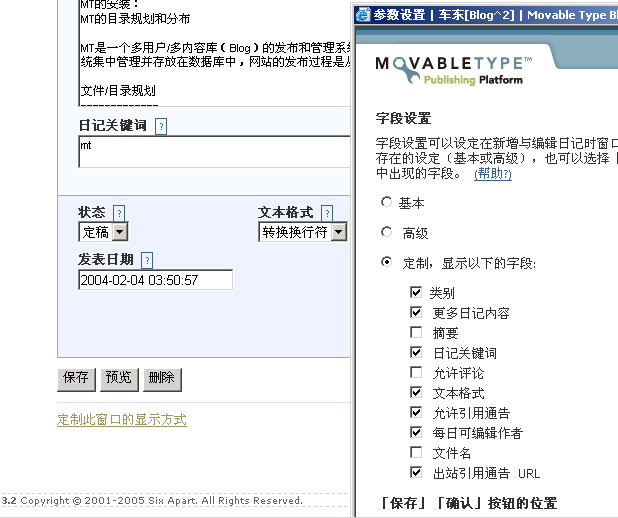
3 在模板中加入:
<MTEntries lastn="6">
<$MTEntryTitle$>
<ul>
<MTRelatedEntriesByKeyword>
<MTEntries lastn="5">
<li><$MTEntryTitle$></li>
</MTEntries>
</MTRelatedEntriesByKeyword>
</ul>
</MTEntries>
以后每次发表文章的时候加上自定义的关键词(可以是多个),就实现了MT文章内部之间基于tagging的类聚。
Analytics: 分析学
发音:[ane'Iitiks]
从2005年3月底收购Urchin,到发布免费的Google Analytics,Google大约用了8个月的时间:而且产品是有中文界面的。
Google搜索本身的点击目标跟踪统计;
带有URL跟踪的toolbar;
Spider的全网抓取;免费的反相代理加速器;互联网上还有什么Google不知道的呢?
我下载了一下urchin.js:做了简单的分析;搜索引擎来源的定义中缺少百度和3721:看来还是太不了解中国市场。和我用AWStats的感觉一样。urchin.js文件大小为17k(这几乎和一个搜索结果页差不多大),假设analytics跟踪每天20亿PV的网站流量,Google每天要为这个服务付出34T bytes的带宽日流量,而20亿PV的日统计计算,尤其在Urchin如此丰富的统计项目下,计算量也是非常大的,硬件投资可是不小啊……
Google发布这样的工具:各种互联网营销工具的效果一目了然,每家搜索引擎的搜索竞价效果好坏对于用户来说都变得非常透明。同时Google对竞争对手的流量也获得了完全的控制。
订阅的Feed越来越多,即使基于简单的配置缓存有时候也经常速度跟不上:网站经常出现只剩下右边半边的情况,就是由于缓存期间抓取远程的网页超时导致的。其实Planet和Gregarius一样,都是在用户访问的时候避免对FEED的动态更新。Planet和Gregarius都是使用后台脚本定时同步FEED,在MagpieRSS外面包了一层存储(数据库),我直接在MagpieRSS中增加了一个只读本地缓存模式。修改了一下MagpieRSS的缓存逻辑:加入一个MAGPIE_LOAD_CACHE_ONLY 模式,只从本地的缓存中取feed,避免更新期间向远程发送FEED同步请求。
然后在lilina前台这样调用即可:
// cache expire in 3 hours
define('MAGPIE_CACHE_AGE', 60 * 60 * 3);
// load cache only
define('MAGPIE_LOAD_CACHE_ONLY', true);
require_once('./lib.php');
按此阅读全文 "lilina(MagpieRSS)的缓存加速II:加入MAGPIE_LOAD_CACHE_ONLY模式" »
不是我不明白,这世界变化快,2年前我用过 EurekSter的搜索引擎,1年前我用过一个叫SWiki的在线服务,前一段时间挂了,转向去了另外一个地方,今天从WebLeOn那里看到:原来变成了SWicki。太奇怪了,一个基于社交网络的搜索引擎(你可以看到你朋友的搜索推荐)怎么变成了一个面向个人的搜索引擎呢?
11月初的中文网志年会上:中文WikiPedian也是其中很出色的一群,在国内看到这样一些为着一个至今仍被阻尼的服务仍然努力着的一群人让我很感动。
wikipedia是一个非常伟大的项目:wiki本身的架构充分体现了Well organized, well referenced with easy navigation的设计. 而更难得的是wikipedia这样一个开发式写作平台其后台良好的协作机制和民主中立的内涵等。这里有一份Wikipedia后台管理员发给我的wikipedia 2005年5月份的统计报告: 点击下载,从中我们可以看到全世界范围内wikipedia的发展和在中文世界的发展情况。
这里我将7月份设置zh.wikipedia.org镜像的过程简要介绍一下:希望有更多的人能够帮助Wikipedia的国内镜像,而从中也能发现:Wikipedia网站结构本身的和目录无关性和域名无关性也是便于镜像的重要原因。在cnblog上使用的apahe配置如下:算是一个使用mod_proxy进行反相代理和mod_cache进行缓存加速的例子吧。
<VirtualHost *:80>
ServerName wikipedia.cnblog.org
ProxyPass / http://zh.wikipedia.org/
ProxyPassReverse / http://zh.wikipedia.org/
CustomLog "|/usr/local/sbin/cronolog /home/apache/logs/wikipedia_cnblog_access_log.%Y%m%d" combined
CacheRoot "/home/apache/cache/zh.wikipedia.org"
CacheSize 500000
CacheDirLevels 1
CacheGcInterval 10
CacheMaxExpire 240
CacheLastModifiedFactor 0.1
CacheDefaultExpire 10
</VirtualHost>
由于近期美国主站访问有阻尼:设置了/etc/hosts 中将zh.wikipedia.org指向其在法国的镜像(也是基于Squid建立的)
# wikipedia.org Europe mirror
145.97.39.155 zh.wikipedia.org
中文Wikipedia7月份以来的后台访问统计:
http://blog.cnblog.org/cgi-bin/awstats/awstats.pl?config=wikipedia
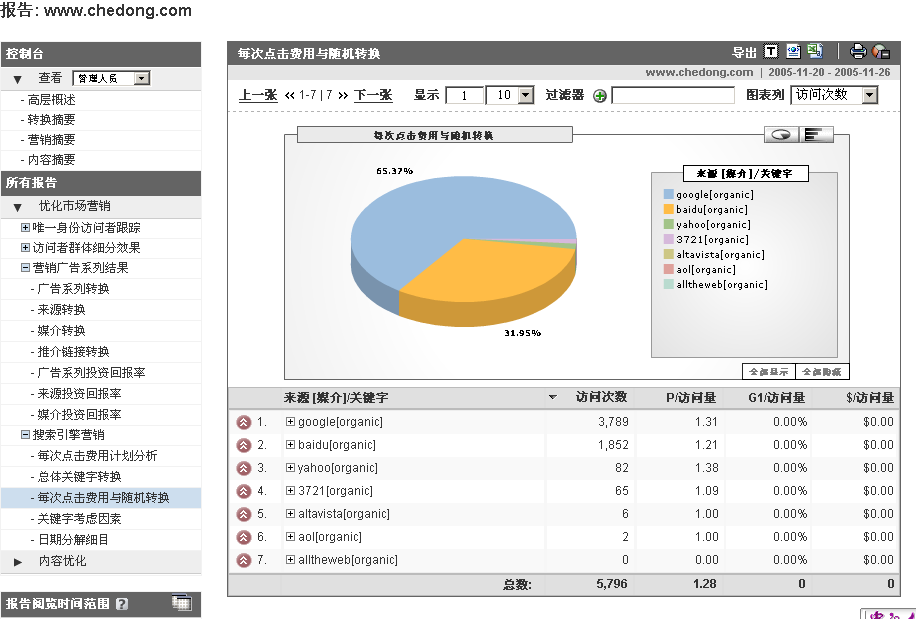
和AWStats一样,Google Analytics完全没有考虑中国的搜索引擎市场中更主要的2个搜索引擎来源:Baidu/3721/soso等搜索引擎的来源,而微软和电信的合作,有道引擎等,如果要计入统计方法也很简单hack一下urchin.js的部署代码即可:
<script src="http://www.google-analytics.com/urchin.js" type="text/javascript">
</script>
<script type="text/javascript">
_uacct = "YOUR_USER_ID";
_uOsr[121]="3721"; _uOkw[121]="name";
_uOsr[122]="baidu"; _uOkw[122]="word";
_uOsr[123]="soso"; _uOkw[123]="w";
_uOsr[124]="vnet"; _uOkw[124]="kw";
_uOsr[125]="yodao"; _uOkw[125]="q";
urchinTracker();
</script>
搜索引擎定义编号最好从120开始:因为analytics对全球各地主要搜索引擎的定义还不断在更新中,目前(2007年12月)已经增加到了33个,
_uOsr[0]="google"; _uOkw[0]="q";
_uOsr[1]="yahoo"; _uOkw[1]="p";
_uOsr[2]="msn"; _uOkw[2]="q";
_uOsr[3]="aol"; _uOkw[3]="query";
_uOsr[4]="aol"; _uOkw[4]="encquery";
_uOsr[5]="lycos"; _uOkw[5]="query";
_uOsr[6]="ask"; _uOkw[6]="q";
_uOsr[7]="altavista"; _uOkw[7]="q";
_uOsr[8]="netscape"; _uOkw[8]="query";
_uOsr[9]="cnn"; _uOkw[9]="query";
_uOsr[10]="looksmart"; _uOkw[10]="qt";
_uOsr[11]="about"; _uOkw[11]="terms";
_uOsr[12]="mamma"; _uOkw[12]="query";
_uOsr[13]="alltheweb"; _uOkw[13]="q";
_uOsr[14]="gigablast"; _uOkw[14]="q";
_uOsr[15]="voila"; _uOkw[15]="rdata";
_uOsr[16]="virgilio"; _uOkw[16]="qs";
_uOsr[17]="live"; _uOkw[17]="q";
_uOsr[18]="baidu"; _uOkw[18]="wd";
_uOsr[19]="alice"; _uOkw[19]="qs";
_uOsr[20]="yandex"; _uOkw[20]="text";
_uOsr[21]="najdi"; _uOkw[21]="q";
_uOsr[22]="aol"; _uOkw[22]="q";
_uOsr[23]="club-internet"; _uOkw[23]="q";
_uOsr[24]="mama"; _uOkw[24]="query";
_uOsr[25]="seznam"; _uOkw[25]="q";
_uOsr[26]="search"; _uOkw[26]="q";
_uOsr[27]="szukaj"; _uOkw[27]="szukaj";
_uOsr[28]="szukaj"; _uOkw[28]="qt";
_uOsr[29]="netsprint"; _uOkw[29]="q";
_uOsr[30]="google.interia"; _uOkw[30]="q";
_uOsr[31]="szukacz"; _uOkw[31]="q";
_uOsr[32]="yam"; _uOkw[32]="k";
_uOsr[33]="pchome"; _uOkw[33]="q";
百度/3721搜索来源统计效果截图:2005年11月
今天尝试了一下StatViz,生成了自己网站的点击路径统计:网站好“扁平”啊;
图较大,点击这里下载
具体的安装过程如下:
下载GraphViz: 一个通用的矢量图生成工具
下载StatViz: 一个基于Web日志生成点击路径矢量结构的工具(PHP脚本)1000多行,生成的.dot文件再使用GraphViz处理生成矢量图了。
辅助安装包:StatViz可能需要PEAR中的Config包:用于解析配置文件。
安装好以上包后: 解包statviz-0.5.tgz
php statviz.php --config=example.conf
就可以生成相应的.dot文件了,其中一个输出文件是汇总的点击pairs统计。
使用StatViz跟踪“用户”点击中,唯一用户缺省是根据同一个IP定义的,就是假设来自同一个IP的为同一个用户,这样定义对于访问量较低的站点可能这样定义没有问题,但是对于访问量较大的站点,来自同一个IP后面有多个用户(比如代理服务器)就不一样了。而同一个用户在不同的时间可能使用不同的IP地址在线。对于这样的情况,要长期跟踪用户行为:使用一个长期有效的Cookie进行用户跟踪是一个比较简便途径。
Apache本身带有一个mod_usertrack模块:其原理就是在用户首次来到当前网站的时候给用户种下一个唯一的cookie(较长时间过期),这个cookie是用户首次来当前网站的IP地址加上一个随机字符串组成的。
1.2.3.4 ... 1.2.3.4.1111 用户1
1.2.3.4 ... 1.2.3.4.2222 用户2
1.2.3.4 ... 1.2.3.4.3333 用户3
第2天,即使用户换了IP,
1.2.1.2 ... 1.2.3.4.1111 用户1
具体的配置方法如下:
1 启用mod_usertrack模块:
LoadModule usertrack_module libexec/mod_usertrack.so
AddModule mod_usertrack.c
2 针对一个域名启用CookieTracking
CookieTracking on
CookieDomain .chedong.com
CookieExpires "10 years"
CookieStyle Cookie
3 mod_usertrack的记录: 在日志最后增加%{cookie}n字段
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %{cookie}n" combined
启用mod_usertrack后的日志样例:
202.160.180.61 - - [30/Nov/2005:17:38:44 +0800] "GET /phpMan.php/man/HTML::AsSubs/3pm HTTP/1.0" 200 4911 "-" "Mozilla/5.0 (compatible; Yahoo! Slurp China; http://misc.yahoo.com.cn/help.html)" 202.160.180.61.227021133343524377
218.249.22.70 - - [30/Nov/2005:17:38:45 +0800] "GET /referer.js HTTP/1.0" 200 26254 "http://bietile.bokee.com/" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" 218.249.22.70.11531133343525235
202.160.180.61 - - [30/Nov/2005:17:38:48 +0800] "GET /phpMan.php/man/File::CheckTree/3pm HTTP/1.0" 200 4654 "-" "Mozilla/5.0 (compatible; Yahoo! Slurp China; http://misc.yahoo.com.cn/help.html)" 202.160.180.61.222451133343528428
然后在StatViz中设置改用最后一个Cookie字段作为唯一用户的跟踪,这样的独立用户会话统计就更准确了:
; Column 0 is the first column -- by default this is the "combined" apache log format, but of course you can customize
LogSessIDColumn=10
...

{kind=link}