昨天看到AWStats的一些扩展统计:ExtraSection真实太有用啦,原先需要grep "index\.xml|index\.rdf|atom\.xml" access_log|awk -F '"' '{print $4}' |sort|uniq -c|sort -rn|head -30 这样的统计用以下配置就可以实现啦,而且有漂亮的表格输出。
ExtraSectionName3="Top RSS Reader/Spider"
ExtraSectionCodeFilter3="200 304"
ExtraSectionCondition3="URL,index\.xml|index\.rdf|atom\.xml"
ExtraSectionFirstColumnTitle3="RSS Reader/Spider"
ExtraSectionFirstColumnValues3="UA,(.*)"
ExtraSectionStatTypes3=HBL
MaxNbOfExtra3=30
MinHitExtra3=1
按此阅读全文 "用AWStats的ExtraSection统计RSS Reader, Spider" »
WordPress已经是非常流行的blog发布系统了,但缺省的blog发布是不支持PermaLink的(可能是考虑到在Windows平台和Apache 2.0上缺省不支持PathInfo)。
将上次从MT迁移到WP的笔记补充一下关于PermaLink的设置:
在WordPress中设置PermaLink的方法:
选项(Option)==>永久链接(Parmalink)设置中:位于 /wp-admin/options-permalink.php
文章详情页结构: /%year%%monthnum%/%day%_%post_id%.html
注意:如果是中文名称的目录,经过UrlEncode编码后的地址无法映射回原来的目录名。
例如:
http://blog.example.com/category/%e9%85%b7%e8%ae%af%e4%ba%a7%e5%93%81/
因此还需要编辑一下每个目录的Slug(分类缩略名)属性:管理==>类别==>编辑类别中,将每个目录设置一个"分类缩略名"。然后类目的输出就会按照英文的分类缩略名进行输出了,例如:
http://blog.example.com/index.php/archives/category/games/
文章页输出样例:
http://www.adayang.com/index.php/2007_01_16_103.html
目录列表页输出样例:
http://www.adayang.com/index.php/category/daily-life
按此阅读全文 "WordPress的永久链接(Permalink)设置" »
在搜索引擎上找了一下《让你免于失业的十项开发技术》这篇文章英文出处在这里:
The 10 Technologies that Will Help You Stay Employed,作者是,Russell Jones
当然:也有人对这10项技术的重要程度有不同的看法,以下是个人的一些感受:
1: XML 这点我看到的是RSS/ATOM这样轻量级的协议已经成为重要的编程接口,但是让XLST等
10: SQL SQL是结构化数据处理的基础,但是现在似乎要加上全文检索技术,全文检索技术是除了:时间/作者/价格等字段外,另外一种将内容之间发布出来的机制,而我们看到的全文搜索引擎也原来越有结构化的影子;
6: Regular Expressions 从正则表达式中受益匪浅,在国外:正则表达式这是一门40个课时的大学课程,在国内:那本99年出版的《Perl 5编程详解》中,有非常详细的一章,很多人都是从那本书开始的
3: Object-Oriented Programming OO编程
7: Design Patterns 设计模式
4: Java, C++, C#, or VB.NET 我将and改成了or,精通其中的一门就够了
2: Web Services WEB服务:MT/WordPress的远程开发接口是最好的教材
5: JavaScript JS是我当时一直不理解的,但是看到GMail/FlickR等很多AJAX实现的在线应用后,知道了自己的浅薄。但是js自身的缺乏可调试性,浏览器兼容性,真正用起来还是挺复杂的。
8: Flash MX Flash依然成为所有浏览器必备的插件之一;
9: Linux/Windows Linux平台的活跃让很多原先非常经典的Unix系统可以被更多一般开发人员接触到,开发人员应该尝试在自己家里开辟实验室。
按此阅读全文 "3年前的旧文:让你免于失业的十项开发技术" »
网志年会也聚集了很多创业的团队,各个团队普遍都对搜索技术非常感兴趣,虽然目的不是和目前大的搜索引擎竞争,但是,通过全文检索技术将自己网站内部和外部的内容更好的相互引用确实是一个普遍的需求。
需求主要是两个方面:
1 站内搜索:站内搜索能便于用户迅速直达相关的内容;
目前很多数据库都提供了全文检索功能,但是对中文的支持优先,另外就是缺乏和其他字段组合的Rank机制。
Lucene可能是目前最常用的非数据库全文引擎,几乎各个语言平台上都有相应,也有一些支持中文分词的解决方案出现。
2 内容类聚:良好的引用能将网站内容之间形成更加网状的结构,也便于SPIDER快速遍历整个网站。
我们看到的Tagging(主题标签),也是实现文章之间通过关键词类聚的一种途径:
优点:比全文引擎实现成本要低,从一篇文章中提取1个或多个关键词,然后将有相同主题的内容类聚在一起。比起传统的目录分类:tagging更好的实现了多对多关系,更符合先写后分类的用户习惯;
缺点:是一种很有趣的造词游戏,但毕竟不能指望所有的用户都会使用10PlacesOfMyCity这样的CamelWord进行内容串联。
另外一个方式就是通过主题引擎的内容类聚:手拉手,以文找文都是这方面很好的实现。
按此阅读全文 "中文网志年会 - [搜索]篇" »
phpMan.php是一个unix上将man page展现在web界面上的php脚本工具,虽然做了一定的防命令行漏洞处理,但是上周还是被LoaA发现了有XSS安全漏洞:
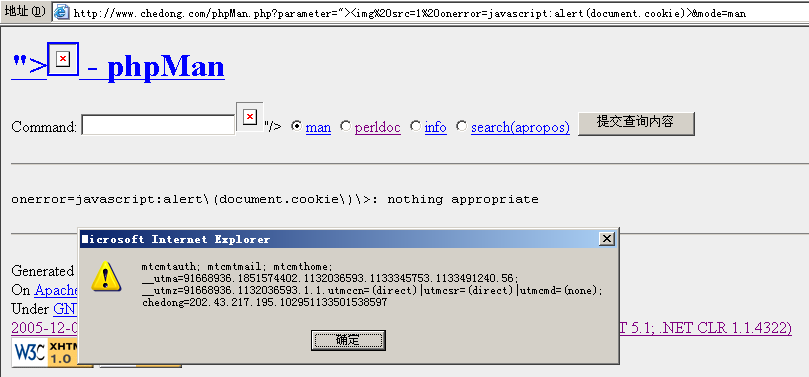
所谓XSS:就是Cross Site Script 跨网站脚本漏洞的缩写。如果纵容这种漏洞有什么危害呢?
上图只是破坏者利用脚本打印除了自己在网站的所有的Cookie列表:我们看到的有mt的后台,有analytics的session,还有最近试验的使用mod_usertrack生成的用户识别cookie。如果这个链接是侵入者诱导其他用户在一个第3方的网站上触发,然后引导用户指向当前网站,然后再利用其他的脚本将用户在当前网站的cookie或其他信息发送到另外一个网站上。流程大致如下:
dirty-web.com/spam email ==user click==> commecial-site.com ==send cookie==> dirty-web.com
这样就完成了一次对用户在一个商业网站上的信息盗取。
按此阅读全文 "phpMan.php中的XSS漏洞(Cross Site Script)" »
毕竟不是所有内容发布系统都支持TrackBack ping机制,另外一个寻找文章被引用的方法就是通过一个搜集了丰富内容的搜索引擎,试下在Google的blogsearch上直接使用 link:命令查: link:chedong.com,再使用RSS/ATOM输出就得到了自己网站内容的引用监控:按时间排序
参考:
Blogger Hack:显示反向链接 - WebLeOn's Blog
按此阅读全文 "利用blogsearch自动发现站外引用" »
从我的网站上看倒的
浏览器分布统计:
十一月份:
1.5好像是上个月底发布的吧
FIREFOX 179581 13.9 %
Firefox 1.5 2.8 %
Firefox 1.0.7 7.8 %
Firefox 1.0.6 0.8 %
本月:
已经上升到7.8
FIREFOX 42531 13.6 %
Firefox 1.5 7.8 %
Firefox 1.0.7 3.9 %
Firefox 1.0.6 0.3 %
虽然有很多插件不兼容了,但是还是升级倒了FireFox 1.5 而新增强的功能让缺省那些tab browsing等插件都不用安装了。
按此阅读全文 "这么快就升级到Firefox 1.5了?" »
java - phpMan
perldoc -f 用于搜perl内置的函数
perldoc -q 用于在perldoc中进行标题的全文检索
按此阅读全文 "给phpMan加上perldoc -f / -q模式" »
前2天在桑林志上看到DreamHost的主机租用方式:桑林志 CPU usage limit 原来是基于每个客户占用的主机CPU的时间:每个虚拟主机客户每天不能超过40分钟。这让我立刻联想到了Sun的CPU 1$/小时的租用服务:
02/01/05 - Sun Lights Up the Sun Grid First Global Compute and Storage Grid for $1/cpu-hr and $1/GB-mo,在目前的硬件和网络环境的发展下:每客户的硬件成本已经可以比较清晰换算了。真正验证了Sun:网络就是计算机的理念。
其实很多在线服务都不能忽视的在线存储技术/CPU/宽带技术硬件技术的发展:也要看到这些新兴服务在控制成本上的努力。搜索和邮件服务应该是非常好的例子。操作系统和开发语言就不用说了:几乎没有用Windows/Solaris等商业操作系统和开发平台的,基于开源软件的非常普遍。而很多在成本上的严格控制是这些服务能够低成本生存/不至于中途夭折的主要原因:
比如:
FlickR:除了用户的易用性上外,我倒是觉得FlickR的免费用户带宽限制技术倒是很重要的因素,否则好好的一个SocialNetworks服务很容易成为色情图片的宿主? 而del.icio.us也非常有效的控制了link spam;
之前我还做过一个BlogLines的成本分析:缓存机制应该是FeedBurner等这些RSS服务的核心。
按此阅读全文 "Web 2.0服务的成本分析:低成本,做你喜欢的事儿" »
今天看到一篇新闻:Firefox users ignore online ads, report says | CNET News.com,更让我惊奇的发现News.com新闻右侧广告下面出现的新相关功能:
通过主题云图的方式展现了相关的文章(黑色),相关的公司(红色)和相关的主题(绿色)
附图如下:
按此阅读全文 "Liveplasma.com的类聚引擎" »
摘自:中国网站首页设计有四大特色:“长,闪,挤,花”
其中很精辟的几段话:
中国网站的页面真是长啊,以至于我坐在电脑前浏览的时候经常会想,这个页面的最低端会不会已经搭拉到我的脚面上了。
科学家已经证实,在月球上是看不到万里长城的,但是我想,应该是可以看到中国网页的,它们不仅长,而且还在不停的闪烁。
按此阅读全文 "中国网站首页设计有四大特色:“长,闪,挤,花”" »
不过还能看到原来必思浓的痕迹……
博客吧主人的官方网站:http://blog.wespoke.com/
还加上了TAG RSS
按此阅读全文 "卢亮/明珠的博客吧开张了……" »
年终小结的时间到了, 2005 年度我最喜欢的几个软件: 是个好题目 整理并推荐一下我在2005常用的软件和在线服务: :
del.icio.us: 我的linklog;
FlickR: 我的photolog, 现在用的比MT 3.2更多;
www.chedong.com: 我用lilina改造的RSS聚合工具. 另外: 不觉得lilina本身应该考虑速度的问题, 因为速度完全取决于RSS同步的策略和缓存的策略. 经过2次优化以后, 我已经更够感受到bloglines和FeedBurner这样的RSS服务商所面临的压力和问题了.
FreeMind: 一个基于java的开源mindmap绘制软件, 是一个做整理思路和做会议纪要的好工具,免费产品中很优秀的一款;
GMail 界面操作效率高, 垃圾邮件少.颠覆了我对webmail的使用习惯 经常使用Gtalk也是因为能当作GMail alert使用.
douban.com: 豆瓣已经达到了拐点,基本上找一本书我会先去豆瓣看看评论
按此阅读全文 "2005 我最喜欢的几个服务" »
最近每天都看DBANotes: 知道了这个工具
Firefox Installed Extensions - ListZilla
安装后我也列了一下常用的插件:
Generated Wed Dec 28 2005 17:16:22 GMT+0800 Enabled Extensions:
Google Toolbar for Firefox 1.0.20051122 Google工具栏:IE上也有
del.icio.us1.0.2 链接收藏 常用,打开新窗口,从原网页上很方便复制/粘贴
LinkChecker 0.4.5 死链检查工具
View Cookies 1.5 查看cookie工具,最近常用
Live HTTP Headers 0.11 http header查看器
Pearl Crescent Page Saver 0.9.3 浏览器屏幕截图工具
ListZilla 0.7 以上列表就是ListZilla生成的
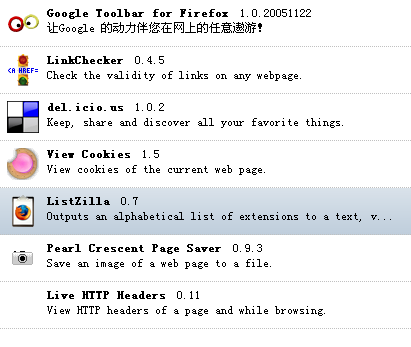 Clusty Toolbar 1.0.6 不常用
Clusty Toolbar 1.0.6 不常用
Performancing 1.0.1 类似于Zoundry的离线blog编写工具 不常用
TWiki Firefox Extension 2.0.3 TWiki格式化工具栏 编写内部文档常用,新版twiki上的可视化编辑器完全可以替代这个插件,而且这个版本在Firefox 1.5.0.1后有不兼容的问题。
按此阅读全文 "Firefox扩展查看器:常用插件列表" »
从最近的流量统计中发现了非常奇怪的现象:某些PV很大的来源流量居然为0
IP地址 国家 PV 流量
69.28.242.87 US 11452 0.28 M字节
64.193.62.232 US 10521 0
66.246.218.107 US 6010 54.59 M字节
69.73.166.108 US 5630 0
61.183.207.98 CN 3047 27.06 M字节
221.11.5.181 CN 2392 66.88 M字节
66.246.120.114 US 2207 0
从原始日志上看:都是类似以下的0流量 HEAD请求
69.28.242.87 - - [29/Dec/2005:13:41:10 +0800] "HEAD / HTTP/1.1" 200 0 "http://bankruptcy.dynu.net/buy-cialis/buy-cheap-cialis.html" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)" 69.28.242.87.253451135834870862
69.28.242.87 - - [29/Dec/2005:13:45:24 +0800] "HEAD / HTTP/1.1" 200 0 "http://medportal.dynu.net/mortgage/" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)" 69.28.242.87.262371135835124636
69.28.242.87 - - [29/Dec/2005:13:52:51 +0800] "HEAD / HTTP/1.1" 200 0 "http://fenikrul.white.prohosting.com/phentermine-online.html" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)" 69.28.242.87.279061135835571753
69.28.242.87 - - [29/Dec/2005:14:04:05 +0800] "HEAD / HTTP/1.1" 200 0 "http://fenikrul.white.prohosting.com/" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)" 69.28.242.87.269751135836245577
69.28.242.87 - - [29/Dec/2005:14:13:17 +0800] "HEAD / HTTP/1.1" 200 0 "http://medportal.dynu.net/buy-viagra/" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)" 69.28.242.87.302561135836797409
每次请求“客户端”只向服务器发送请求,但是目的是为了能将referer中的地址被统计到当前网站的统计系统中,如果统计系统是对外公开的话而且是有超链形式的链接的话(虽然几率非常低),搜索引擎的spider抓取到以后,就会被计坐指向spam网站的链接。一个机器人每天可以对千万级的网站进行referer发送。只要其中十万分之一的网站能够对其中的"中招",大量的反向链接就制造出来了。而被连接的网站可以轻易的得到很高的
PageRank;而spam所付出的代价仅仅是向这些网站发送一些空请求的少量带宽. 如何防止这样的HEAD请求呢,谁知道有什么模块可以滤掉这些流量?
按此阅读全文 "遭遇Referer Spam" »
日志统计分析:年底流量小结 刚好用上WebLeon那里学到的FireFox截屏插件
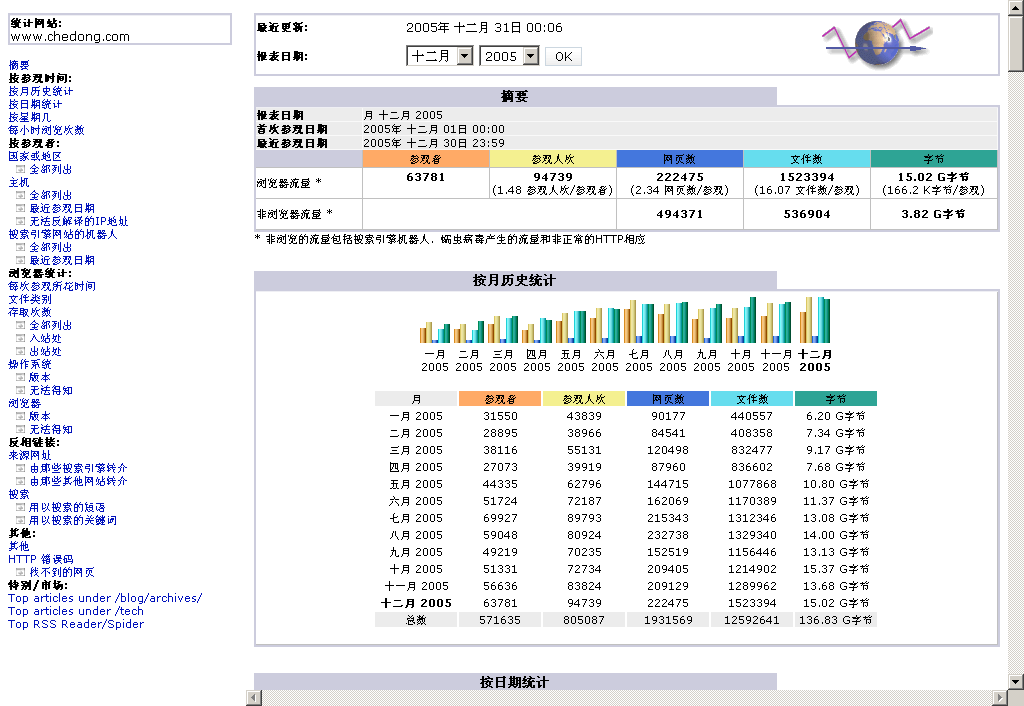
2005年chedong.com主要使用了以下几套系统:
首页生成: Lilina/MagpieRSS
Blog发布: MT del.icio.us Flickr
流量分析: AWStats, Google Analytics
点击统计: mybloglog.com
referer统计: Booso的referer引擎
感觉:
CMS的各个环节都在向向在线的服务发展;
然后通过RSS/JS将各种服务粘合起来;
按此阅读全文 "年终总结:2005 chedong.com 年终小结" »





 图上是这个域名发布后首日的来源统计分析.
图上是这个域名发布后首日的来源统计分析.