Last year, Justin Cutroni of
EpikOne published a four-part tutorial on how to use Ecommerce Tracking in Google Analytics. We've seen a lot of interest in this topic, so we thought we'd republish the first part of the series here on the Analytics blog.
Ecommerce Tracking Part 1: How it Works
This post is the first in a series of e-commerce transaction tracking with Google Analytics. Why is e-commerce tracking important? Well, transaction data is a vital piece of information when analyzing online business performance.
Sure, it’s great to measure things like conversion rate, but revenue is much more tangible to many business owners. Having the e-commerce data in your web analytics application makes it easier to perform analysis. Do you need to set up e-commerce tracking? No, but it sure helps. :)
The Big Pictures
E-commerce tracking is based on the same principal as standard pageview tracking. JavaScript code sends the data to a Google Analytic servers by requesting an invisible gif file. The big difference is that e-commerce data is sent rather than pageview data.
But how does Google Analytics get the e-commerce data? That’s the tricky part. You, the site owner, must create some type of code that inserts the transaction data into the GA JavaScript. Sounds tricky, huh? Well, its not that bad.
Step by Step: How it Works
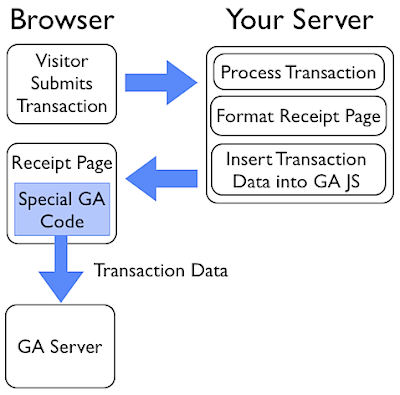
Let’s break it down and walk through what actually happens.
- The visitor submits their transaction to your server.
- Your server receives the transaction data and processes the transaction. This may include a number of steps at the server level, such as sending a confirmation email, checking a credit card number, etc.
- After processing the transaction the server prepares to send the receipt page back to the visitor. While preparing the receipt page your server must extract some the transaction data and insert it into the Google Analytics JavaScript. This is the code that you must create.
- The receipt page is sent to the visitor’s browser.
- While the receipt page renders in the visitor’s browser the e-commerce data is sent to Google Analytics via special GA JavaScript.
- Here’s a basic diagram of the process. Again, the biggest challenge during implementation is adding code to your web server that inserts the transaction data, in the appropriate format, into the receipt page. I’ll cover the setup in part 2 of this series.
What Data can be Tracked?
Google Analytics collect two types of e-commerce data: transaction data and item data. Transaction data describes the overall transaction (transaction ID, total sale, tax, shipping, etc.) while item data describes the items purchased in the transaction (sku, description, category, etc.). All of this data eventually ends up in GA reports. Here’s a complete list of the data:
Transaction Data
- Transaction ID: your internal transaction ID [required]
- Affiliate or store name
- Total
- Tax
- Shipping
- City
- State or region
- Country
Item Data
- Transaction ID: same as in transaction data [required]
- SKU
- Product name
- Product category or product variation
- Unit price [required]
- Quantity [required]
A few notes about the data. First, the geo-location data is no longer used by Google Analytics. The new version of GA tries to identify where the buyer is located using an IP address lookup.
Also, you should avoid using any non-alpha numeric characters in the data. Especially in the numeric fields. Do not add a currency identifier (i.e. dollar sign) in the total, tax or shipping fields. this can cause problems with the data.
Continue reading parts 2-4 of this series on EpikOne's Blog, Analytics Talk
Posted by Sebastian Tonkin, Google Analytics

 |
|  |
|  |
|  |
| 

